Query outcome
The CINTIL Online Concordancer permits to retrieve passages with occurrences of a given target expression in the CINTIL corpus.
The target expression is entered in the query text box. The retrieved passages are displayed below that box.
When the "Show tags" box is checked, the concordancer displays also the linguistic annotation.
For each token, this annotation is displayed between square brackets, with a
colon separating each field. For instance, the annotation for the common
noun carros will be displayed as follows:
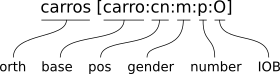
Note that this annotation is displayed in a slightly different format than the one used in the corpus release. For a description of the latter, check here.
For practical reasons each passage returned with the occurrence contains at most 10 tokens.
Also for practical reasons, not all passages with occurrences of the target expression in the CINTIL corpus are returned. Also, the order in which the passages are displayed does not correspond to a possible consecutive order of their occurrence in the corpus. Note however that the outcome of the CINTIL online concordancer can be used as a reference in research given that identical queries return identical outcome.
In those usage cases where it is imperative to have access to every occurrence, the interested user can acquire a copy of the corpus and run a concordancer of his choice over that local copy.
Searching orthographic forms
- Case-sensitiveness
- Search is case-sensitive. For a case-insensitive search, append
/ito the orthographic form:- by entering
gato, occurrences of gato are obtained gato/igets occurrences of gato, Gato, GATO, etc.
- by entering
- Sub-sequence matching
- The query expression match whole tokens. For instance
gatowill not match parts of words, and will not return regato or obrigatoriamente.To allow sub-sequence matching, append
/xto the orthographic form (which can be combined with the/imentioned previously).For instance:
gatowill only match gatogato/xwill match any word containing the string gato, such as obrigatoriamentegato/xiis as above, but case-insensitive
- Contractions
- Note that in the CINTIL corpus the contractions (e.g. daquela,
aos, nas) are reverted and encoded with two tokens, where
the first is concatenated with an underscore symbol (e.g.
de_ aquela,a_ os,em_ as)
Searching for patterns
It is possible to search with general pattern (regular expressions). A query can thus include regular expressions, provided it is enclosed in quotes. The usual notational conventions are followed:
- Alternation
- Alternatives are introduced by the
|(vertical bar) character:"gato|peixe"matches all occurrences of gato and all occurrences of peixe
- Character sets
- A set of characters within square brackets match occurrences of any of
those characters:
"gat[ao]"match occurrences of gata and gato"[pg]at[ao]"will match occurrences of gata, gato, pata and pato
^(caret) symbol immediately after the opening bracket."[^abcd][efg]"matches tokens with two characters, the first one not being a, b, c or d and the second one being e, f or g
- Period
- The
"."(period) match any single character (letter, digit or symbol):"gat.s"will match gatas, gatbs, gatcs, gat1s, etc.
- Optionality
- The
"?"(question mark) permits that the character/expression preceding it is optionally matched:"gatos?"matches gato and gatos.
- Iteration
- There are three forms of expressing iteration. The
*(star) operator permits that the character/expression preceding it is matched zero or more times:"gat.*"matches any word starting with gat, including gat itself".*gato.*"matches any word containing the string gato (this is equivalent togato/x)
+(plus) operator is similar, but enforces that there is at least one occurrence of the character/expression preceding it:"gat.+"matches any word starting with gat, but not gat since+enforces at least one occurrence
{l,u}permits that the number of iterations is bounded by a lower (l) and an upper (u) value. Note that either bound may be omitted. In such cases,{l,}means "at leastltimes",{,u}means "at mostutimes" and{n}means "exactlyntimes":"gat.{2,4}"matches words that start with gat and that have 2 to 4 additional characters"[^aer]{5,}"matches words without a, e or r that have 5 or more characters.
- Grouping
- Parentheses are used to group expressions. The operators described above
can then be applied to the whole expression in parentheses as if it was
a single character:
"gat(inh)?o"matches gato and gatinho (i.e. the sequence inh that follows t is optional)"ga(to)*"matches ga, gato, gatoto, gatototo, etc. (i.e. to may occur zero or more times)
Note that any of these expressions may also be modified by the
/i and /x described previously.
For instance:
"ga.*"/imatches words starting with ga, Ga, gA or GA"(ra){2}"/xmatches words that contain two consecutive occurrences of ra (e.g. rara, mostraram, etc.)
Searching through linguistic information
Each token is associated to linguistic information, encoded by means of annotation tags. Each tag is composed of a field and its value in square brackets ([field=value]). For example, [gender=m], [time=pi], etc.
Each field is instantiated by a keyword.
The values can be matched with any of the methods described above:
[field=pattern]is the format for such queries.
Field-pattern pairs can be combined by using logical operators:
& (ampersand) for conjunction and | (vertical bar)
for disjunction:
[field=pattern & field=pattern][field=pattern | field=pattern]
In addition, the negation symbol ! (exclamation) permits to
match tokens whose field values do not conform to a given pattern:
[!field=pattern]is one format for such negation[field!=pattern]is equivalent to the previous query.
Orthographic form (again)
The orthographic form itself can be matched via the keyword
orth:
[orth=gato]matches tokens with the orthographic form gato. This returns the same result as simply searching forgato. Using this alternative but equivalent way is useful when combiningorthwith other fields (to be discussed below)[orth="gat.*" & orth!=gato]matches tokens that begin with gat but that are not gato
Part-of-speech
Selecting occurrences with a given part-of-speech (POS) category is done by
resorting to keyword pos:
[pos=cn]matches tokens with the POS tag cn (common noun)[pos=cn & orth="ga.*"]matches tokens that are common nouns and begin with ga[pos="d.*"]matches tokens with any POS tag whose name begins with d[pos!=pnt]matches tokens that are not punctuation (the pnt tag)
The list of POS tags may be consulted under the "Tagsets" tab at the top of this panel.
Nominal inflection
The keywords gender and number have, respectively,
the values f (feminine) or m (masculine), and the
values s (singular) or p (plural). They permit to
match occurrences with selected inflection features:
[gender=f]matches all tokens with feminine inflection[number=s & orth=".*s"]matches all tokens with singular inflection that end in s[gender!=m]matches tokens that do not have masculine inflection. Note that this also matches those tokens to which gender inflection is not even applicable, such as prepositions, punctuation, symbols, etc.
Some tokens may bear degree features, accessed through the
degree keyword:
[degree=dim]matches all tokens with diminutive degree
Verbal inflection
In order to match tokens according to their verbal inflection features, one
can resort to person, time and number
keywords:
[person="1"]matches tokens inflected for first person[time="ppi"]matches tokens inflected for the Pretérito Perfeito Indicativo[person="3" & number="s" & time="fc"]matches all forms expressing the third person singular of Futuro Conjuntivo[person!="1"]matches tokens that do not have 1st-person inflection. Note that this also matches those tokens to which person inflection is not even applicable, such as prepositions, punctuation, symbols, etc.
The list of verbal inflection tags may be consulted under the "Tagsets" tab at the top of this panel.
Infinitives can occur inflected or not inflected. This information is matched
through the inflection keyword.
Lemma
In order to match tokens by their lemma, the base keyword can be
used:
[base=rato]matches words with rato as their base form (lemma), such as rato, ratos or ratinho, etc.[pos=cn & base=".*s"]finds common nouns whose lemma ends in s[orth=foi & pos=v & base!=ir]matches occurrences of the verb form foi that do not belong to verb ir
Named-entity
To match tokens according to their being part of an expression naming an
entity, the iob keyword is used:
[iob=B-LOC]matches tokens that are the beginning (B-) of an expression naming an entity whose semantic type is "location" (LOC).[iob=I-PER]matches tokens that are inside (I-) an expression naming an entity of type "person" (PER).
The list of named-entity tags may be consulted under the "Tagsets" tab at the top of this panel.
Metadata
It is possible to use metadata to restrict the match to a given type of text
through the use of the meta command:
gato meta source=writtennewsmatches gato only in the news portion (writtennews) of the corpusgato meta source="written.*"matches gato only in the written portion of the corpus (includeswrittennews,writtenficitonandwrittenother)
For a list of metadata fields and values, see the "Quick reference" tab at the top of this panel.
Advanced queries
Through the combination of the different search options described above, it is possible to construct advanced queries and uncover relevant linguistic information:
situação[pos=adj]returns the occurrences of the word situação followed by an adjective[pos=da][pos=cn]return the occurrences of a definite article (the da tag) followed by a common noun[pos=da][pos=adj]?[pos=cn]is similar to the previous query, but allows a single, optional adjective (indicated by the adj tag) between the definite article and the common noun[pos="cn|adj"]{3,}returns sequences with at least 3 consecutive adjectives and common nouns (in any relative order)[pos=da][pos!=cn]{2,3}[pos=adj]returns sequences of a definite article followed by 2 or 3 tokens that are not common nouns and that are followed by an adjective- ... etc.
Aligning matches
It is possible to split the outcome of the query into two columns to make it
more readable by using the ^ (caret) symbol:
[pos=da][pos!=cn]{2}^[pos=adj]matches a definite article followed by 2 tokens that are not common nouns, followed by an adjective. The definite article and the following 2 tokens will be displayed in a column while the final adjective will be shown in a column by itself.
Query syntax cheat sheet
| Basic query | |
|---|---|
| a word matches itself | |
| Query modifiers | |
/i |
case-insensitive match |
/x |
sub-sequence matching |
| Character expressions | |
. |
any single character |
[ ] |
character from a set |
[^ ] |
character from negated set |
| Repetition operators | |
|---|---|
? |
optional |
* |
zero or more times |
+ |
one or more times |
{n} |
exactly n times |
{n,} |
n or more times |
{,n} |
up to n times |
{m,n} |
from m to n times |
| Combining expressions | |
|---|---|
e1e2
|
e1 followed by e2
|
| |
alternation |
( ) |
grouping |
| Search by annotation | |
[keyword=expression] |
|
[keyword!=expression] |
|
[key1=exp1 & key2=exp2]
|
|
[key1=exp1 | key2=exp2]
|
|
Regular expressions must be enclosed in quotes.
Contractions are reverted and encoded as two tokens, where the first is
concatenated with an underscore.
Quick reference
| Field | Keyword | Values |
|---|---|---|
| Orthographic form | orth |
any |
| Part-of-speech tag | pos |
full table |
| Inflection feature | gender |
f, m, g |
number |
s, p, n |
|
degree |
dim, sup, comp |
|
person |
1, 2, 3 |
|
time |
full table | |
inflection |
ifl, nifl
| |
| Lemma (base form) | base |
any |
| Named-entity | iob |
full table |
| Metadata | source |
writtennewswrittenfictionwrittenotherspoken |